- 基础类型
- string、list、set、hash、zset
- hash、set = ziplist + dict
- list = ziplist + quicklist
- zset (Sorted Set)
- skiplist + dict
- 本质二分查找的有序链表
- string、list、set、hash、zset
- 底层类型 (复用底层类)
- 其他类型
- module、streams (Fewly Used, just acknowledge them)
历史原因,Redis 4.0 引入了模块扩展功能,当时已经认为是最后一个类型,但是 Redis 5.0 又引入了 Stream 数据结构,可能是觊觎 Kafka 的市场份额
- module、streams (Fewly Used, just acknowledge them)
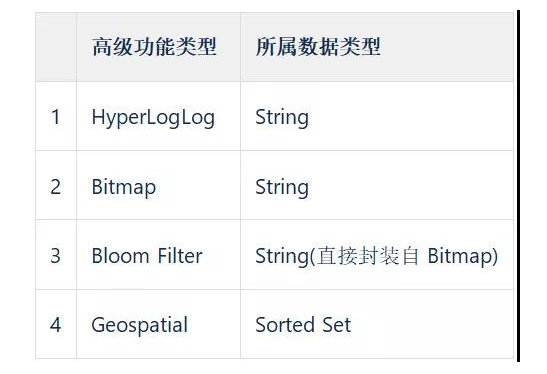
- 高级功能封装
- HyperLogLog、BitMap、BloomFilter、Geo、CuckooFilter

细说细节🤠
- ziplist 的连锁更新 prevlen空间压缩策略prevlen 属性会根据前一个节点的长度进行不同的空间大小分配:
- 如果前一个节点的长度< 254 字节,那么 prevlen 属性需要用 1 字节的空间来保存这个长度值。
- 如果前一个节点的长度>= 254 字节,那么 prevlen 属性需要用 5 字节的空间来保存这个长度值。
当一个很大的元素插入到头节点后,经过内存重分配后,后续prevlen更新,占用由1变5 bytes,同时自己的length更新(变大),这就导致它的下一个节点的prelen也要更新,这样连锁反应导致从头到尾遍历更新,性能变差。
- ziplist -> listpack (进化)
- 在 Redis5.0 出现了 listpack,目的是替代压缩列表,其最大特点是 listpack 中每个节点不再包含前一个节点的长度,压缩列表每个节点正因为需要保存前一个节点的长度字段,就会有连锁更新的隐患。
- 结构体
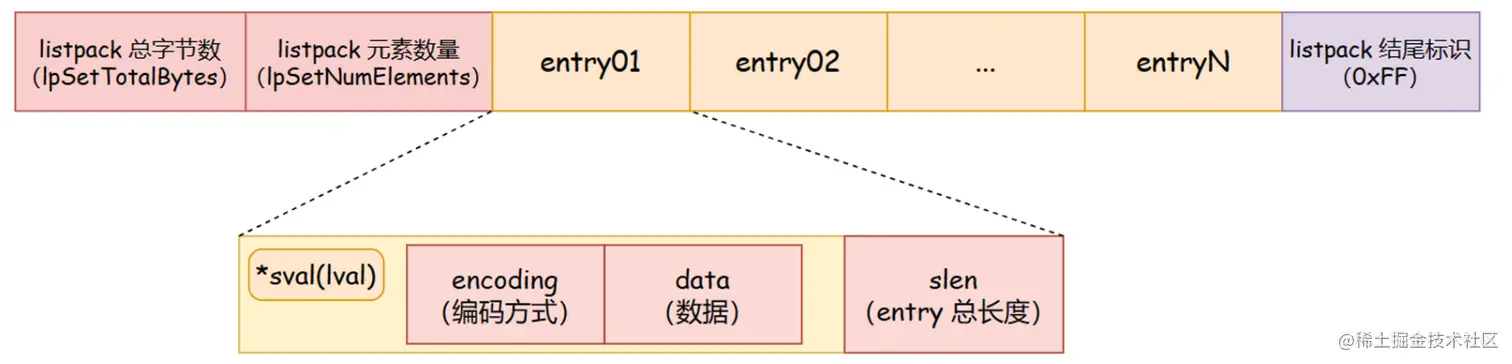
typedef struct {
unsigned char *sval; /* 当是字符串时,sval为字符串首地址,否则 sval 为 NULL。 */
uint32_t slen; /* 当字符串时,slen 表示字符串的长度。如果为整数则忽略该段。 */
long long lval; /* 当整数时,lval 存储整数的值。如为字符串则忽略该段。 */
} listpackEntry;
- 正向遍历简单,我们主要看看反向遍历
- listpack 的反向遍历,主要的难点在于如何找到当前节点的上一个节点,而这一点主要是依靠逐字节前移动,将前一个节点的slen读取出来
- slen由于特殊二进制编码规则让其能够知道slen是否已经读取完毕,这样就把自己节点储存上一节点的大小的问题,转化成了我往前遍历,在前一个节点末尾读到它自己的大小。
- 如果保存的是整数,整个结构体只有一个long long lval;在32、64位OS下都是64位长度,前面几位用于表示实际长度,这时候不需要slen字段,因为一个8字节int64遍历到头也开销不大。 > [不同操作系统下int 、指针、long、long long大小](https://www.yuque.com/u26180163/zp8dwe/ughz0r21lkegq2u4?view=doc_embed)
- 正向遍历时,如果是lval,那下一位直接+8字节即可;如果是sval,同样字符串头部前几位也是编码标识实际长度的,同样根据拿到encoding类型获得串长度,直接跳末尾再+4字节的slen字段即可到下一个节点。 - 为什么Redis选择使用跳表而不是红黑树来实现有序集合?
先来看 Redis 中的有序集合(zset) 支持的操作:
1. 插入一个元素
2. 删除一个元素
3. 查找一个元素
4. 有序输出所有元素
5. **按照范围查找(区间查找)元素(比如查找值在 [100, 356] 之间的数据)**
其中,前四个操作红黑树也可以完成,且时间复杂度跟跳表是一样的。但是,按照区间来查找数据这个操作,红黑树的效率没有跳表高。按照区间查找数据时,跳表可以做到 O(logn) 的时间复杂度定位区间的起点,然后在原始链表中顺序往后遍历就可以了,非常高效。