1.字节序
默认Intel或AMD的x86/x64架构就一定是小端字节序。 外很多ARM CPU可以选择数据指令字节序,不过通常也都是运行小端字节序(比如我们的智能手机)。
在第三版本之前ARM架构是小端模式,之后是两种模式都允许,可以进行设置来切换字节序列。例如,在 ARMv6 上,指令是固定的小端,数据访问可以是小端或大端,由程序状态寄存器 (CPSR) 的位 9(E 位)控制。 MIPS, MACOS是大端
- 大端:由于malloc分配内存是从低地址到高地址分出一片区域,而装填数据如果是从高位到低位装填(也就是高位填低位)就是大端序,同时大多数内存浏览窗口都是从0x0~0xFFFFFFFF正向浏览,这样视觉效果上和人类观看一个数的观感一致。
- 小端:默认操作系统可以视为小端,也就是看上去每个字节都反过来存放了,随便截取一条mov指令看看mov由一个字节(双hex=4位)BA表示,后面操作数可以看到左端内存里展现正好和这个数本身字节存放是相反的。

2.网络序
网络序默认采取了大端序。 原因:
- 简化处理: 大端字节序在数据传输和处理时更易于操作。在大端字节序中,最重要的字节位于最前面,这与人类的阅读习惯更为一致。这样,通信双方在处理数据时可以更直观地操作最高有效位。
- 可靠性和稳定性: 大端字节序在网络通信中更容易进行数据的逐字节传输和解释。这有助于避免数据解释错误,提高通信的可靠性和稳定性。
- 历史原因: 早期的计算机体系结构和网络协议都倾向于使用大端字节序。这些历史原因使得大端字节序成为网络通信的事实标准。
3.位序/比特序
bit序本身也存在每一位和地址之间存放顺序关系,其次序和大小端是一致的,即默认小端操作系统里面提取出一个字节BA,即 ,看内部实际是:0101 1101。 但是问题在于,我们调用htonl时候,也就是小端序转大端序时候,并没有同时把字节序从大端模式转小端,因为我们任意打印一个字节时候没有说会出现翻转现象。 这个问题其实间接交给网卡处理了,因为网络序才会用到hton系列函数,在传递大端bytes给目标网卡时候,对面会直接按照bytes大端读,bits小端读载入; 网卡规定:字节内部直接把8位从低位到高位发送给os和从os接收; 操作系统如果是小端呢,比特序也就是小端,我就按little endian解析成uint8_t; uint32_t htonl(uint32_t hostlong); uint16_t htons(uint16_t hostshort); uint32_t ntohl(uint32_t netlong); uint16_t ntohs(uint16_t netshort); Host to Net (long) Host to Net (short) Net to Host (long) Net to Host (short) 不同操作系统下int 、指针、long、long long大小 也就是说,网络字节序大端不考虑内部比特位转化,双方都默认低位到高位写出和读入;
,看内部实际是:0101 1101。 但是问题在于,我们调用htonl时候,也就是小端序转大端序时候,并没有同时把字节序从大端模式转小端,因为我们任意打印一个字节时候没有说会出现翻转现象。 这个问题其实间接交给网卡处理了,因为网络序才会用到hton系列函数,在传递大端bytes给目标网卡时候,对面会直接按照bytes大端读,bits小端读载入; 网卡规定:字节内部直接把8位从低位到高位发送给os和从os接收; 操作系统如果是小端呢,比特序也就是小端,我就按little endian解析成uint8_t; uint32_t htonl(uint32_t hostlong); uint16_t htons(uint16_t hostshort); uint32_t ntohl(uint32_t netlong); uint16_t ntohs(uint16_t netshort); Host to Net (long) Host to Net (short) Net to Host (long) Net to Host (short) 不同操作系统下int 、指针、long、long long大小 也就是说,网络字节序大端不考虑内部比特位转化,双方都默认低位到高位写出和读入;
4.结构体、位域和大小端
位域结构体不能看成一整个变量,它实际上就是单纯的从低地址逐个存入,不考虑内存对齐而已。 因此不用考虑结构体读入是大端还是小端的问题,它是以内部标准变量一个个读入并顺序装填的。 但是位域结构体如果把它在网络流上传输后,就会被按照比特流或者字节流(大端形式)进行写出,和远端读入; 这时候如果远端系统是小端系统(最常见的amd-x86-64\amd64,intel\x86)那还原的时候就就是从低地址读入 例如:  由于第一个成员在低地址,在内存中:
由于第一个成员在低地址,在内存中: 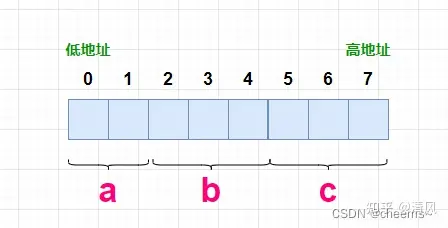 赋值令其(a,b,c)=121=0111 1001
赋值令其(a,b,c)=121=0111 1001
具体地,网卡在发送数据时,通常会按照先发送低位比特,然后发送高位比特的顺序进行传输。而在接收数据时,网卡会将接收到的比特序列转换成主机的字节序,以便 CPU 和软件正确解释和处理数据。 这种转换是透明的,即 CPU 和软件不需要关心数据传输过程中的比特顺序转换,它们可以按照自己的字节序进行操作。这种机制有助于不同设备在网络通信中进行协作,使得数据能够在不同字节序之间正确传递和解释,而不需要额外的手动处理。
也就是说网卡针对一个字节内部比特序列进行了处理,使每个字节都变成对应操作系统所需的大小端字节序了,因此我们开发不用关注比特序,只需要处理好字节序
是的,您理解得很正确。网络适配器(网卡)在数据传输过程中会处理内部的比特序列,以确保每个字节都符合操作系统所需的大小端字节序。这种处理是在硬件层面上进行的,因此开发者无需直接关注比特序的转换。开发者只需要处理好字节序,确保数据在不同设备之间以正确的字节序进行传输和解释。 在开发网络应用程序时,您只需要考虑如何正确地处理数据的字节序,而不需要显式地进行比特序的转换。通过使用合适的字节序转换函数或库,您可以确保数据在不同平台上都能够正确地传输和解释,从而实现跨平台的通信。网络适配器会在底层处理比特序的转换,使开发者能够更专注于应用程序的逻辑。
我的理解是,在网络传输过程中,接收方B和发送方A处理数据都是按大端序进行数据的处理解析,这个行为是网络层到应用层的处理逻辑;而在网卡C在其中扮演的角色是针对数据链路层的处理逻辑,文中定义的大端主机是指存储的比特序排列是大端,小端主机指比特序是小端;在比特流的传输上由主机网卡统一定义为先发MSB,即权重最高的bit数据。假设小端主机发送数据给大端主机,数据位于bit7,那么bit0-bit7的权重为bit7所在的位置是MSB,bit0所在的位置是LSB。网卡传输是先传输bit7所在位置的数据,按照bit7,bit6,bit5,bit4,bit3,bit2,bit1,bit0的顺序发送。另一个主机网卡接收时,先接收到的是MSB,即bit7,根据网卡所在主机的比特流大小端存储,若是大端,此bit7对应的MSB数据就会被存放在接收主机的内存bit0的位置。这样就实现了大小端的bit序的映射; 综上,你对于文章中的说法疑问是对的,因为楼主写错了。其中”大端序发送给小端序“的配图中写道的”网卡发送转换小端序“是错误的说法。 应该纠正的是“先发低位bit再发高位bit的顺序发送”这句话,改为”先发最高权重bit即MSB(bit),最后发送LSB(bit)”. 其中对于MSB的英文:Most significant byte/bit ;
来了,结构体位域一般配合协议里报文的次序进行声明,这里需要考虑次序 Q: 一般网络协议都是大端序,大端序低地址存储高位,所以如果主机是小端序,则按照协议规定反着定义位域即可。因为大小端序转换的话,bit位置就是逆序 这个如何理解?如果我用位域结构体定义,每个字节包含的成员需要相反顺序定义?才能满足协议官方报文中的顺序? 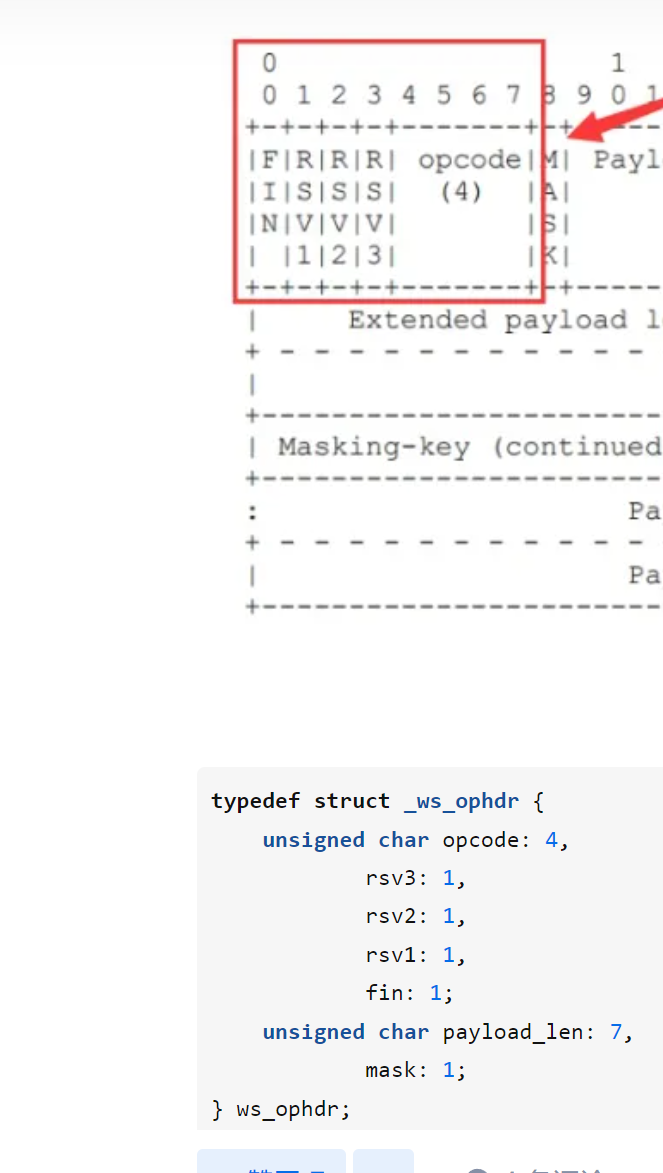 A:
A:
如果您的主机是小端序(即高位字节存储在高地址,低位字节存储在低地址),在处理网络协议时,您需要按照协议规定的大端序来处理数据。这意味着您需要反着定义位域的顺序,以确保数据的比特位置是逆序的,从而与协议的大端序保持一致。 例如,如果协议中要求一个字段的高位字节在前,低位字节在后,而您的主机是小端序,那么您在位域结构体中定义该字段时,需要将高位字节定义在后面,低位字节定义在前面,以反着的顺序表示。 这样做是为了在数据传输和解释过程中,能够正确地与网络协议进行交互,以满足协议的规定。通过逆序定义位域,您可以在小端序主机上正确处理大端序的网络协议数据。